

Here at Billups, our data science and engineering teams are a tight-knit bunch—often collaborating to weave their work into our business to allow for the production of cutting-edge data science and technology. To illuminate some of the work that is happening behind the scenes at Billups, we’re rolling out a new series of blog posts called the Billups Innovation Lab; a monthly exposé of some of the coolest, most exciting things happening with data science and technology.
At the forefront of this collaboration, we’re continually working to offer the most effective measurement & attribution for out-of-home advertising—the latter of which can show a direct correlation with an increase in sales or visits to a physical store due to a particular advertising campaign.
An essential ingredient to our solution for this problem is (anonymized) positional mobile device data and the behavioral inferences we can make from it. We start with timestamped GPS coordinates and then literally connect the dots to produce a continuous trip across a map.
In a nutshell, we start with this:
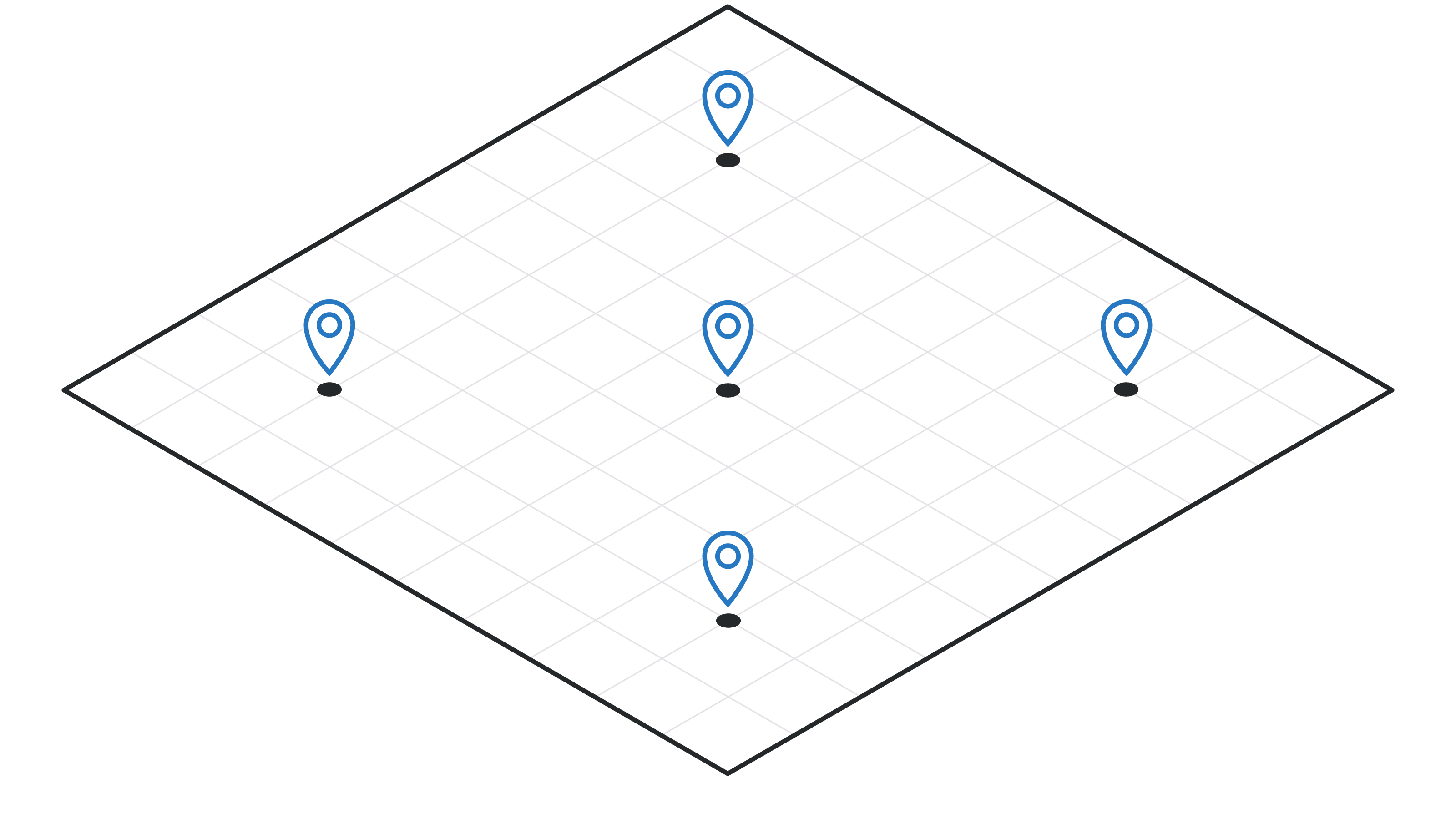
and end up with this:
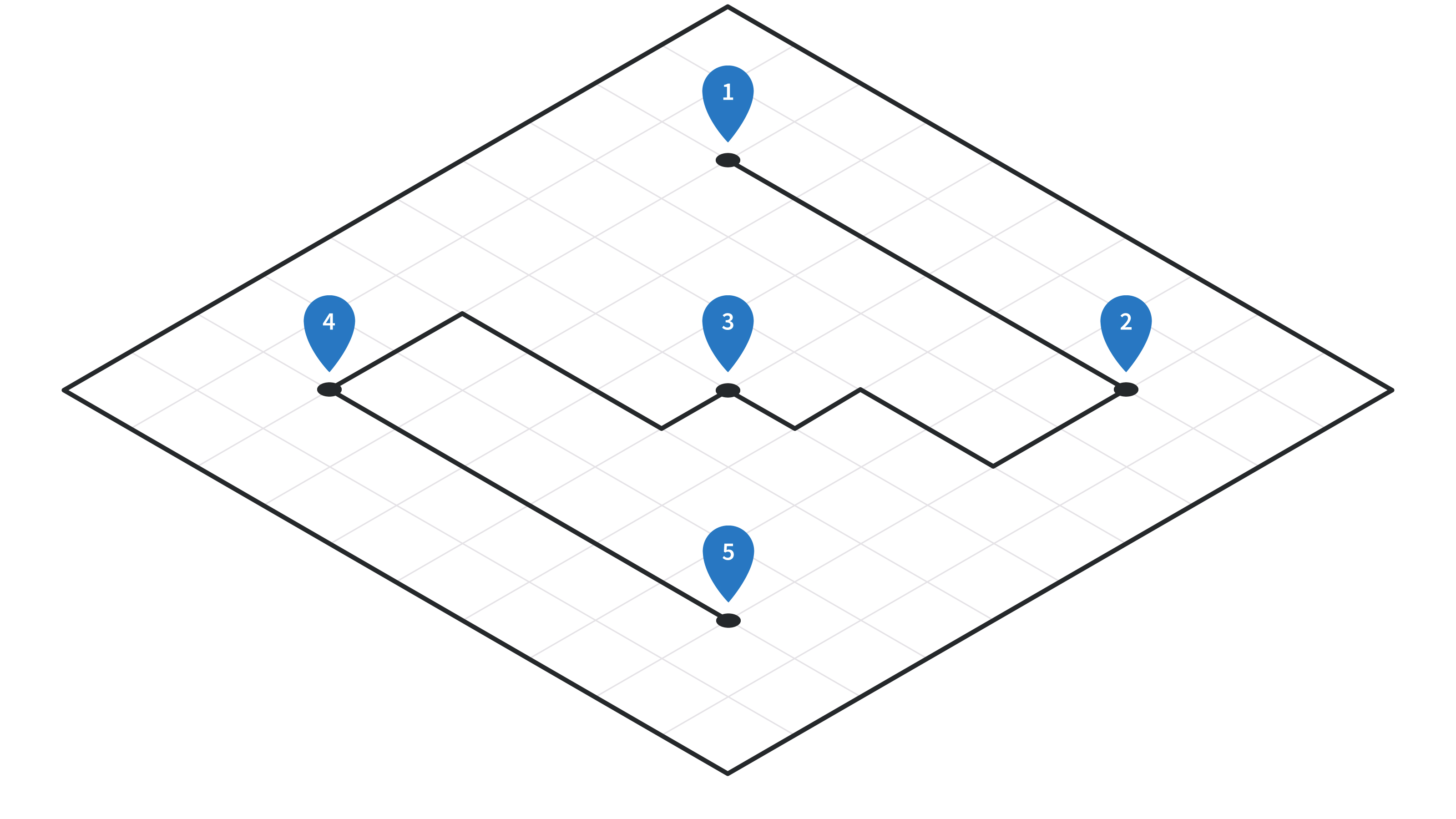
To get to this point, our data science team had to get a solution up and running to use for our current attribution efforts. However, there’s so much data processing involved (for example, we took in 85.2 billion mobile device traces for the month of April alone), they were forced to do things like limit the scope to specific markets. As such, they approached the engineering team for help scaling up and speeding up the processing.
After many questions were asked, we developed an understanding of the first version of the solution: first, in Apache Spark, we grouped traces from each device together with traces from the same device to form checkpoints along a trip. Then, we used the driving directions API which is part of the software Valhalla to infer the most likely route the driver took. Finally, we used Valhalla again to convert the driving route into a list of road edges, which are stretches of road between decisions drivers can make—like “should I turn left?” or “should I take this exit off the freeway?”
That all seemed nice and simple, so we dove into the technology involved. As it turned out, it was taking 80 Spark servers to keep 10 Valhalla servers busy, which made it pretty clear that Spark (and the tasks it was responsible for) was the main bottleneck. And after looking around for—and not finding—an existing tool that met our needs, we decided that since those needs were both simple and highly specialized, our best option was building our own software to replace Spark.
We knew we had an embarrassingly parallel problem, and we knew that each trip taken by a driver didn’t need to take into account any of the other trips, so we decided on a pipeline architecture—which can be thought of like an assembly line: each thing moves from stage to stage along the pipeline and each stage has one specialized job.
Keeping computational complexity in mind every step of the way, we built software to replace Spark in this process using the Go programming language. The result was a system that was considerably faster and more efficient. This brought the processing time down from 12 hours per day (15 days per month) to about 30 minutes per day (15 hours per month) and, because of the efficiency, brought down the estimated cost considerably.
This was a huge win for us for three main reasons. It gave us the headroom to improve the sophistication of our models, studies, and analyses. It also reduced the lead time between receiving a request for an attribution report and being able to actually begin the analysis necessary to complete it. And it tightened the timeline in our innovation loop, allowing us to iterate and improve our methods more rapidly.
All in all, we were thrilled with the result, and are looking forward to the exciting innovations it will enable and support for our data science and engineering teams. Interested in learning more? Reach out to us today!



